Este artículo muestra cómo instalar el DNIe en Debian GNU/Linux Stretch (9) aunque puede aplicar total o parcialmente a otras versiones de GNU/Linux.
Otras versiones: DNIe en GNU/Linux.
Introducción al DNIe
Puedes pasar directamente a la instalación si lo prefieres.
Una vez instalado un lector de DNI-e, también nos sirve para utilizar tarjetas criptográficas CardOs M4 como las que utiliza por ejemplo la Comunidad Valenciana a través de la ACCV.
El DNI electónico o DNIe se puede hacer funcionar en GNU/Linux, tanto para identificarse en webs como para firmar documentos todo con plena validez legal. El problema es que a la hora de hacer los drivers hubo varias chapuzas, problemas con las licencias libres, utilización de librerías incorrectas… Pero el proceso es sencillo una vez lo conoces.

No hay que olvidar que el DNIe tiene sus limitaciones y pegas de seguridad. (Para los “paranoicos” se recomienda utilizar el DNIe únicamente desde sistemas de solo lectura como un CD con Knoppix).
Tampoco hay que olvidar que una firma “normal” es mucho más facil de falsificar que una firma electrónica, pese a que ninguna sea totalmente segura.
Lo primero que hay que saber es que en el DNIe tenemos a nuestra disposición dos certificados, uno para identificarnos (certificado de autenticación) y otro para firmar (certificado de firma), lo que son los dos principales usos del DNIe.
También es importante saber que cada aplicación que utiliza el DNIe establece una “sesión” con el lector de tarjetas y que no puede haber dos sesiones abiertas a la vez. Es decir no podemos usar el DNIe en dos aplicaciones a la vez. Sin embargo muchas aplicaciones no indican adecuadamente esta circunstancia y simplemente parece que no funcionan.
Así por ejemplo si iniciamos sesión en iceweasel/firefox para acceder a una web, no podemos firmar un archivo pdf con sinadura hasta cerrar sesión. Y al revés, tras firmar un fichero con sinadura no nos deja validarnos con iceweasel.
Ante la duda basta con extraer y volver a introducir el DNIe en el lector para asegurarse que está disponible el acceso.
Un último recordatorio, si se introduce el PIN del DNIe erróneamente tres veces seguidas, éste se bloquea. Así que al hacer pruebas con los programas y sus configuraciones hay que tener cuidado. A mí se me bloqueó haciendo pruebas con Sinadura (para desbloquearlo hay que pasar 5 minutos por una comisaria), así que después cada vez que hacía una prueba con un programa si no funcionaba perfectamente iniciaba sesión en iceweasel/firefox.
INSTALACIÓN DEL LECTOR Y LA VERSIÓN DE OPENSC PARA EL DNIe
Como administradores instalamos los paquetes del repositorio:
# aptitude install pcscd pcsc-tools pinentry-gtk2 opensc
generamos un enlace que se queda perdido:
# ln -s /usr/lib/x86_64-linux-gnu/libpcsclite.so.1 /usr/lib/
descargamos e instalamos el paquete de DNI-e:
# wget https://www.dnielectronico.es/descargas/distribuciones_linux/libpkcs11-dnie_1.5.0_amd64.deb # dpkg -i /home/guimi/xxxxx/libpkcs11-dnie_1.5.0_amd64.deb
¡Ya está instalado! Ahora hagamos unas comprobaciones y veamos como configurarlo y usarlo…
Comprobaciones
Podemos comprobar si el sistema reconoce correctamente el lector con el comando “pcsc_scan” y probando a introducir y sacar el DNIe (u otras tarjetas similares):
$ pcsc_scan PC/SC device scanner [...] Reader 0: ACS ACR 38U-CCID 00 00 Card state: Card inserted, [...] Possibly identified card (using /usr/share/pcsc/smartcard_list.txt): XX XX XX XX XX XX XX XX XX XX XX XX XX XX XX XX XX XX XX XX DNI electronico (Spanish electronic ID card) http://www.dnielectronico.es Reader 0: ACS ACR 38U-CCID 00 00 Card state: Card removed,
Otras pruebas que podemos hacer son:
$ opensc-tool -l Readers known about: Nr. Driver Name 0 pcsc C3PO LTC31 (00426664) 00 00 $ opensc-tool -a Using reader with a card: C3PO LTC31 (00426664) 00 00 xx:xx:xx:xx:xx:xx:xx:xx:xx:xx:xx:xx:xx $ opensc-tool -n Using reader with a card: C3PO LTC31 (00426664) 00 00 dnie
USO Y DISFRUTE
Identificarse en sitios web con Firefox
El DNIe se puede utilizar al navegar para identificarse en un sitio web. Así por ejemplo si nos identificamos en la web de la seguridad social podremos descargarnos al instante nuestra vida laboral y en la pagina de la agencia tributaria podremos hacer todos los trámites de nuestra declaración de la renta.
Primero debemos registrar en Iceweasel/Firefox el módulo de DNIe PKCS#11.
Abrimos el programa, navegamos a “about:preferences#privacy” y pulsamos sobre “Dispositivos de seguridad…“. Seleccionamos “Cargar”, indicamos un nombre, por ejemplo “DNIe OpenSC PKCS#11”, y la ruta del módulo “/usr/lib/libpkcs11-dnietif.so”.

Si la instalación ha sido correcta y tenemos el lector conectado con un DNIe introducido, nos habilitará la opción “Iniciar sesión” (¡bien!). Puede ser necesario reiniciar el programa.
Si iniciamos sesión nos pedirá el PIN/Clave.
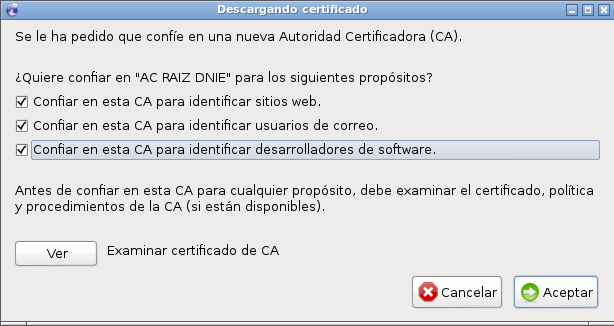
De nuevo desde “about:preferences#privacy” pulsamos sobre “Ver certificados… -> Importar…” e importamos los certificados del DNI-e:
/usr/share/libpkcs11-dnietif/ac_raiz_dnie.crt /usr/share/libpkcs11-dnietif/FNMTClase2CA.crt
confiando en ellos para todo.
Comprobaciones
Podemos probar nuestro DNIe en el navegador en la página de verificación de la FNMT.
Si todo ha ido bien el navegador nos pide nuestro PIN para iniciar sesión (si no lo hemos introducido antes):

Cuando conectamos con una web en la que debemos identificarnos nos pregunta cuál de los dos certificados (el de firma o el de autenticación) queremos utilizar. Para identificarnos usamos el de autenticación.

Si el navegador nos indica:
El otro extremo de la conexión SSL no puede verificar su certificado.
(Código de error: ssl_error_bad_cert_alert)
Es porque no hemos iniciado sesión correctamente (hemos fallado el PIN 3 veces, no lo hemos puesto, no está bien instalado el lector…).
Lo recomendado es “Iniciar sesión” en el navegador solo cuando se necesita y “Terminar sesión” lo antes posible. Si visitamos una página que requiere certificado sin haber iniciado sesión, el navegador nos solicitará el PIN automáticamente, pero para cerrar sesión hay que ir “a mano” a la opción “Dispositivos de seguridad” del menú o sacar el DNIe del lector.
Firmar archivos PDF con Sinadura
Otro uso interesante del DNIe es firmar un archivo PDF. Esta firma tiene plena validez legal. Es decir, hasta ahora había que hacer un documento, imprimirlo y después firmarlo a mano. Ahora podemos hacer un documento, guardarlo como PDF (por ejemplo con OpenOffice Writer) y después firmarlo con nuestro DNIe.
Hay que insistir en que tiene plena validez legal. Sirve para hacer contratos, compra ventas, reclamaciones…
Firma digital con Debian GNU/Linux y Sinadura
Más posibilidades
Una de las posibilidades que la gente busca es firmar y/o cifrar correos electrónicos con el DNIe.
Hay que decir que técnicamente se puede pero que su validez legal es cuanto menos dudosa, y como lo que se busca con el DNIe es tener validez legal no es muy práctico. Siempre se puede enviar un correo-e “normal” con un pdf firmado como adjunto, por ejemplo un contrato.
Esto es porque técnicamente para firmar y/o cifrar basta con tener un par de claves pública/privada, pero el estándar internacional PKI requiere, para firmar un correo-e, que el certificado de la clave indique una dirección de correo-e, que será la única que se “certificará”. Sin embargo en el DNIe no se indica ninguna dirección de correo-e, por lo que no se puede utilizar las firmas del DNIe para este fin.
Lo más recomendado es firmar y cifrar con claves GPG, u obtener firmas de la FNMT, que sí están preparadas para este propósito.